I am currently working with Martin Klein, Matteo Cancellieri and Herbert Van de Sompel on a project funded by the European Open Science Cloud Pilot that aims to test and benchmark ResourceSync against OAI-PMH in a range of scenarios. The objective is to perform a quantitative evaluation that could then be used as evidence to convince data providers to adopt ResourceSync. During this work, we have encountered a problem related to the scalability of ResourceSync and developed a solution to it in the form of an On Demand Resource Dump. The aim of this blog post is to explain the problem, how we arrived to the solution and how the solution works.
Highlights
The problem
One of the scenarios we have been exploring deals with a situation where the resources to be synchronised are metadata files of a small data size (typically from a few bytes to several kilobytes). Coincidentally, this scenario is very common for metadata in repositories of academic manuscripts, research data (e.g. descriptions of images), cultural heritage, etc.
The problem is related to the issue that while most OAI-PMH implementations typically deliver 100-1000 responses per one HTTP request, ResourceSync is designed in a way that requires resolving each resource individually. We have identified and confirmed by testing that for repositories with larges numbers of metadata items, this can have a very significant impact on the performance of harvesting, as the overhead of the HTTP request is considerable compared to the size of the metadata record.
More specifically, we have run tests over a sample of 357 repositories. The results of these tests show that while the speed of OAI-PMH harvesting ranges from 30-520 metadata records per second, depending largely on the repository platform, the speed of harvesting by ResourceSync is somewhere in the range of only 4 metadata records per second for harvesting the same content using existing ResourceSync client/server implementations and sequential downloading strategy. We are preparing a paper on this, so I am not going to disclose the exact details of the analysis at this stage.
As ResourceSync has been created to overcome many of the problems of OAI-PMH, such as:
- being too flexible in terms of support for incremental harvesting, resulting in inconsistent implementations of this feature across data providers,
- some of its implementations being unstable and less suitable for exchanging large quantities of metadata and
- being only designed for metadata transfer, omitting the much needed support for content exchange
it is important that Resource Sync performs well under all common scenarios, including the one we are dealing with.
Can Resource Dumps be the solution?
An obvious option for solving the problem that is already offered by ResourceSync are Resource Dumps. While a Resource Dump can speed up harvesting to levels far exceeding those of OAI-PMH, it creates some considerable extra complexity on the side of the server. The key problem is that it creates the necessity to periodically package the data as a Resource Dump, which basically means running a batch process to produce a compressed (zip) file containing the resources.
The number of Resource Dumps a source needs to maintain is equal to the number of Capability Lists it maintains times the size of the Resource Dump Index. The minimum practical operational size of a Resource Dump Index is 2. This is to ensure we don’t remove a dump currently being downloaded by a client during the creation of a new dump. As we have observed that a typical repository may contain about 250 OAI-PMH sets (Capability Lists in the ResourceSync terminology), this implies the need for a significant data duplication and requirements on period creation of Resource Dumps if a source chose to use Resource Dumps as part of the harvesting process.
On Demand Resource Dumps
To deal with the problem, we suggest an extension of ResourceSync that will support the concept of an On Demand Resource Dump. An On Demand Resource Dump is a Resource Dump which is created, as the name suggests, whenever a client asks for it. More specifically, a client can scan through the list of resources presented in a Resource List or a Change List (without resolving them individually) and request from the source to package any set of the resources as a Resource Dump. This approach speeds up and saves processing on the side of both the source as well as the client. Our initial tests show that this enables ResourceSync to perform as well as OAI-PMH in the metadata only harvesting scenario when requests are sent sequentially (the most extreme scenario for ResourceSync). However, as ResourceSync requests can be parallelised, as opposed to OAI-PMH (due to the reliance of OAI-PMH on the resumption token), this makes ResourceSync a clear winner.
In the rest of this post, I will explain how this works and how it could be integrated with the ResourceSync specification.
There are basically 3 steps:
- defining that the server supports an on-demand Resource Dump,
- sending a POST request to the on-demand dump endpoint and
- receiving a response from the server that 100% conforms to the Resource Dump specification.
I will first introduce steps 2 and 3 and then I will come back to step 1.
Step 2: sending a POST request to the On Demand dump endpoint
We have defined an endpoint at https://core.ac.uk/datadump . You can POST it a list of resource identifiers (which can be discovered in a Resource List). In the example below, I am using curl to send it a list of resource identifiers in JSON which I want to get resolved. Obviously, the approach is not limited to JSON, it can be used for any resource listed in a Resource List regardless of its type. Try it by executing the code below in your terminal.
curl -d ‘[“https://core.ac.uk/api-v2/articles/get/42138752″,”https://core.ac.uk/api-v2/articles/get/32050″]‘ -H “Content-Type: application/json” https://core.ac.uk/datadump -X POST > on-demand-resource-dump.zip
Step 3: receiving a response from the server that 100% conforms to the Resource Dump specification
The server responds by sending back the resources packaged as a Resource Dump. So, this is the whole demo.

So, you can see above that I can unzip the file on-demand-resource-dump.zip which I obtained by POSTing the request. You can see that it has a manifest (as required by the ResourceSync spec) and then the two resources requested from the server. Now, what is very neat about this, in my opinion, is that it not only saves the number of HTTP requests that need to be issued and responded to, but as the response is compressed, it also saves bandwidth.
Step 1: Defining that the server supports an On Demand Resource Dump.
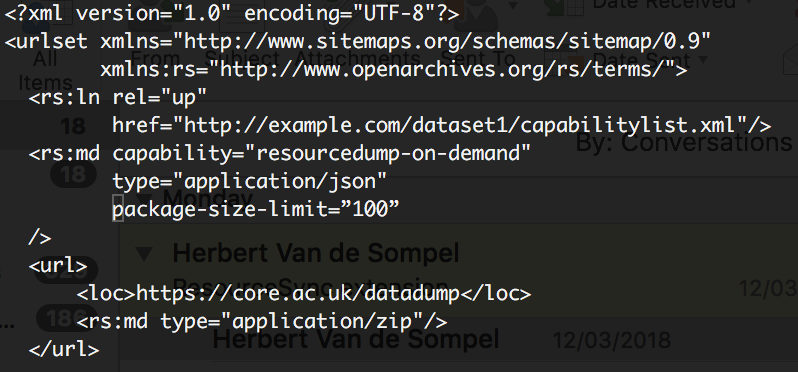
Now, I am coming back to the question of how should a client know where the On Demand endpoint is and how to use it, i.e. how should a server declare the On Demand Resource Dump endpoint. After discussing this with Herbert, we feel that the best way might be to define it in the same way as Resource Dumps are defined in the current ResourceSync specification, but with the addition of some new properties. For example, like this:
![]()
This would declare that the server supports calling an On demand API at https://core.ac.uk/datadump POSTing a list of resources in the JSON format that should be resolved and returned in the form of a Resource Dump. The maximum supported size of the list on the server is 100 items.
Conclusions
On Demand Resource Dumps are an approach that can simplify the adoption of ResourceSync. They can be very easily supported by data providers, providing good performance in metadata only harvesting tasks, while not requiring the periodic execution of batch processes to create new Resource Dumps. On Demand Resource Dumps are also useful for harvesting of the most recent resources in situations where a Resource Dump or a Change Dump exist, but are slightly out of date, as the approach is much faster than resolving every resource individually.