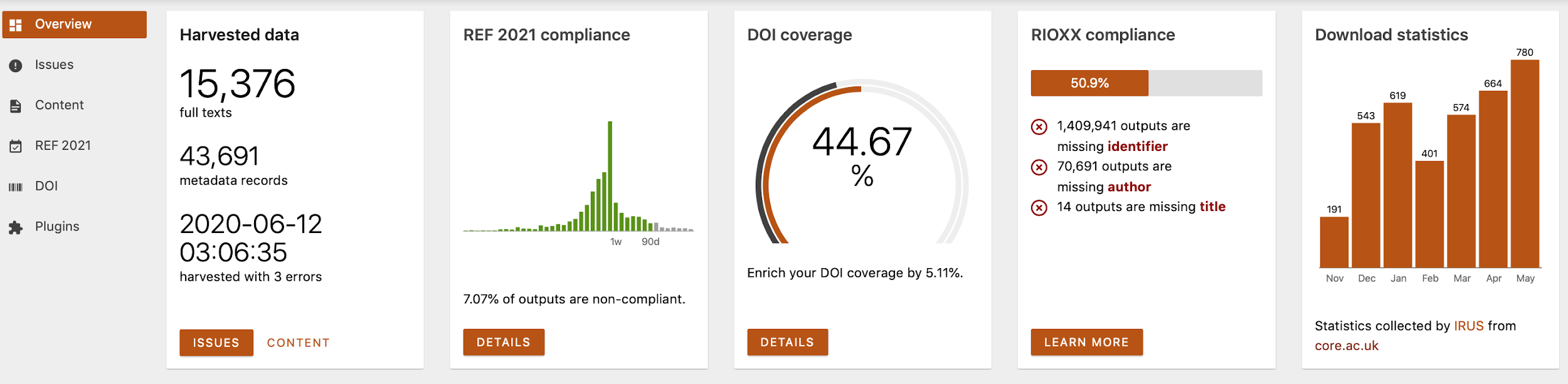
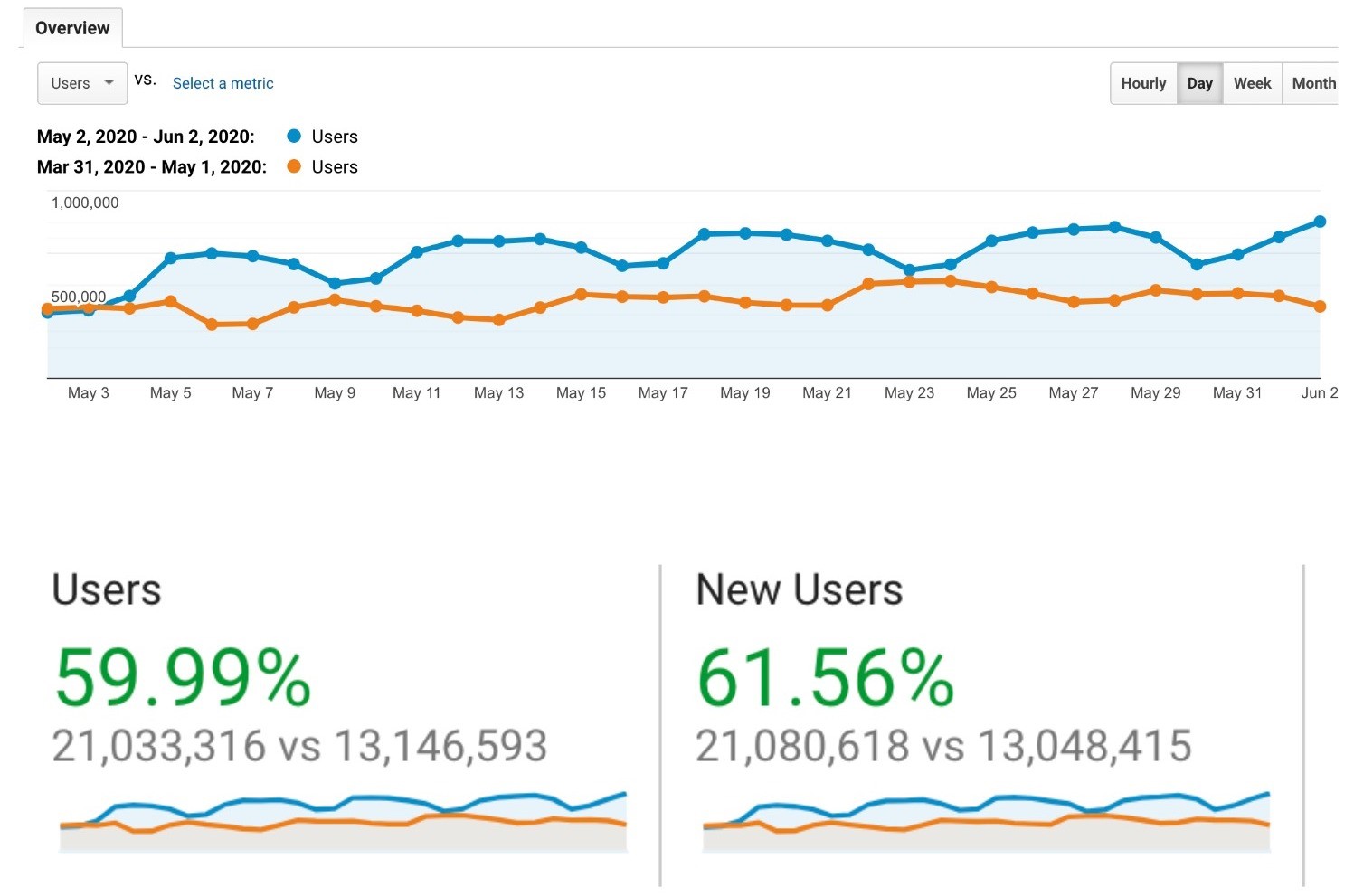
In December 2022, we launched the CORE Membership program for data providers. CORE is a not-for-profit service dedicated to the open access mission and one of the signatories of the Principles of Open Scholarly Infrastructures POSI. We have since seen this membership grow to over 30 institutions who have committed to supporting CORE, and the membership program is now a key component of CORE’s long term sustainability plan.

Our wonderful CORE members!
Today we are extremely happy to announce the latest addition to our membership roll. The University of Glasgow has committed to support CORE as a sustaining member for the next five years. This is a fantastic public commitment and we are extremely grateful to the team at Glasgow for their support and acknowledgement for the work that CORE does.