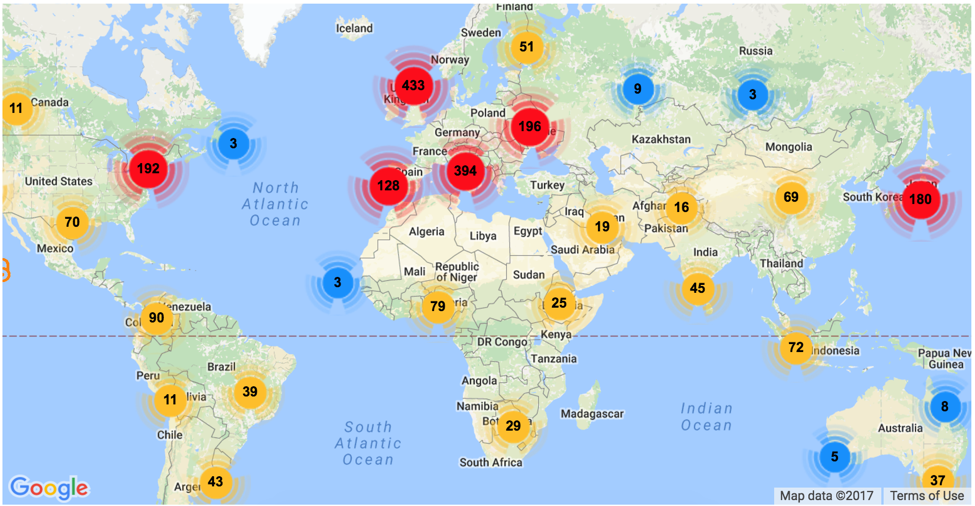
An online editing and proofreading company, Scribendi, has recently put together a list of top 21 freely available online databases. It is a pleasure to see CORE listed as Number 1 resource in this list. CORE has been included in this list thanks to its large volume of open access and free of cost content, offering 66 million of bibliographic metadata records and 5 million of full-text research outputs. Our content originates from open access journals and repositories, both institutional and disciplinary and can be accessed via our search engine. In addition, we also offer an API and Datasets for programmable access to this content, enabling the development of new artificial intelligence-based applications for scientists and for carrying out text and data mining of scientific literature.