The first quarter of the new year was very productive for the CORE team with a number of new releases.

More about it can be found on the Jisc Research blog.
![]()
The first quarter of the new year was very productive for the CORE team with a number of new releases.
More about it can be found on the Jisc Research blog.
We’re delighted to announce a new partnership between CORE and Arabic Digital Reform Institute (ADRI), providing services to researchers to store, share and access Arabic academia online.
The partnership will provide ADRI with unlimited access to millions of open access articles to provide research platform and repository services to academics all over the world.
The detailed information about this is available on the Jisc Research blog.

Since the start (10 years ago!) CORE’s mission has been to aggregate and facilitate access to Open Access scientific research at an unprecedented scale to both humans and machines. To achieve this aim, we are always refining and improving our methods for access and use of the CORE data.

A key consideration in making improvements is that CORE users hail from many different backgrounds and are applying the CORE tools in a variety of use-cases. At last count, we had over 40 broad industry types (including academic research, education, publishing, software, and technology companies) applying the CORE tools to their work across the world. Applications of CORE tools and data are growing and constantly changing.
Much of CORE Team’s focus involves developing services that underpin open research. The updates for this half-year include numerous examples of this in action. You can find details about these and more news on the Jisc Research blog.
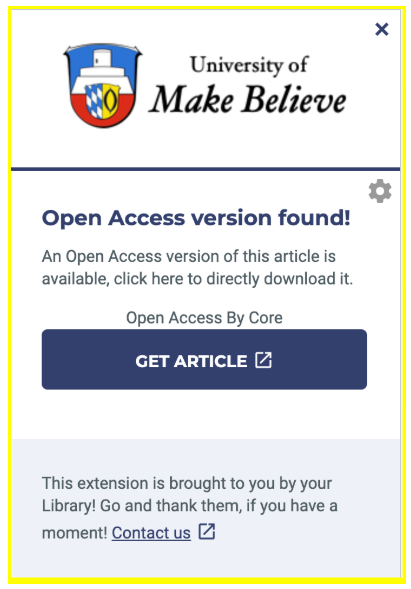
CORE follows its mission and makes open access more visible and reusable by being an enabling infrastructure. This time CORE joins its forces with Lean Library, whose aim is to provide seamless access to research materials for users. Due to this collaboration with Lean Library, the CORE Discovery service will now be indirectly used by library systems integrating Lean Library, thereby reaching more users. More information about this integration can be found here.

An online editing and proofreading company, Scribendi, has recently put together a list of top 21 freely available online databases
. It is a pleasure to see CORE listed as Number 1 resource in this list. CORE has been included in this list thanks to its large volume of open access and free of cost content, offering 66 million of bibliographic metadata records and 5 million of full-text research outputs. Our content originates from open access journals and repositories, both institutional and disciplinary and can be accessed via our
As a result, it means that we will stop supporting old versions of the recommender. If you installed the recommender on or before the 10th October 2016, you will need to upgrade.
Any old version of the recommender will cease to work on Monday 20th February 2016.
In EPrints, visit ‘Admin’, ‘System Tools’, ‘Eprints Bazaar’. In the list of installed plugins, if you see ‘CORE Widget’ or version 0.x.x, then you will need to upgrade. For example, if you see the following information, you will need to upgrade:
Notice how the title is CORE Widget and the website link is core.kmi.open.ac.uk.
If you are on the latest version, you will see the name as ‘CORE Recommender’, the version will be 1.x.x. An example of this is:

Here, the title is CORE Recommender and has a link to our new website address https://core.ac.uk.
For non-EPrints installations:
We previously offered a Javascript installation process. The best way to know if you need to upgrade is if the API key you are using is longer than 20 characters. If you are still unsure, please get in touch.
No, you will need to register for a recommender ID. Your existing API key will continue to be valid for our API v2 requests.
If you need any help with upgrading or have any further questions, please contact us or write a comment below. We’ll be happy to help.
 We are pleased to announce that we have released a new version of our dataset, which contains data aggregated by CORE in a downloadable file.
We are pleased to announce that we have released a new version of our dataset, which contains data aggregated by CORE in a downloadable file.
It is intended for (possibly computationally intensive) data analysis. Here you can read the dataset description and the download page. If you need fresh data, and your requirements are not computationally intensive, you can also use our API.
11th Annual Conference on Open Repositories
{kind=link}