by
George Macgregor, Institutional Repository Coordinator, University of Strathclyde
This guest blog post briefly reviews why the CORE Recommender was quickly adopted on Strathprints and how it has become a central part of our quest to improve the interactive qualities of repositories.
Back in October 2016 my colleagues at the CORE Team released their Recommender plugin. The CORE Recommender plugin can be installed on repositories and journal systems to recommend similar scholarly content. On this very blog, Nancy Pontika, Lucas Anastasiou and Petr Knoth, announced the release of the Recommender as a:
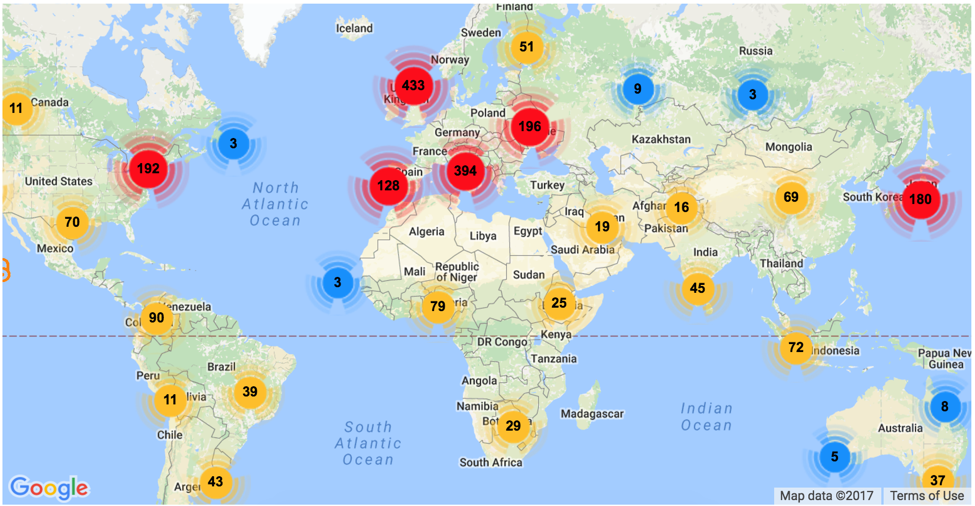
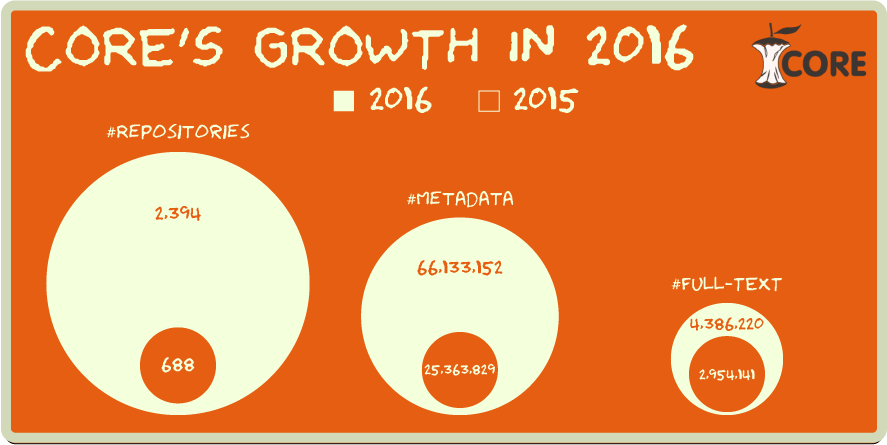
…great opportunity to improve the functionality of repositories by unleashing the power of recommendation over a huge collection of open-access documents, currently 37 million metadata records and more than 4 million full-text, available in CORE*.
(* Note from CORE Team: the up-to-date numbers are 80,097,014 metadata and 8,586,179 full-text records.).
When the CORE Recommender is deployed a repository user will find that as they are viewing an article or abstract page within the repository, they will be presented with recommendations for other related research outputs, all mined from CORE. The Recommender sends data about the item the user is visiting to CORE. Such data include any identifiers and, where possible, accompanying metadata. The CORE response to the repository then delivers CORE’s content recommendations and a list of suggested related outputs are presented to the user in the repository user interface. The algorithm used to compute these recommendations is described in the original CORE Recommender blog post but is ultimately based on content-based filtering, citation graph analysis and analysis of the semantic relatedness between the articles in the CORE aggregation. It is therefore unlike most standard recommender engines and is an innovative application of open science in repositories.
Needless to say, we were among the first institutions to proudly implement the CORE Recommender on our EPrints repository. The implementation was on Strathprints, the University of Strathclyde’s institutional repository, and was rolled out as part of some wider work to improve repository visibility and web impact. The detail of this other work can be found in a poster presented at the 2017 Repository Fringe Conference and
a recent blog post read more...