Highlights
CORE releases CORE Discovery in Mozilla and Opera browsers
![]() CORE Discovery, a browser extension that offers one-click access to free copies of research papers whenever you might hit a paywall, is now published in Mozilla and Opera Stores. The plug in was originally released as a Google Chrome extension.
CORE Discovery, a browser extension that offers one-click access to free copies of research papers whenever you might hit a paywall, is now published in Mozilla and Opera Stores. The plug in was originally released as a Google Chrome extension.
CORE presents its full texts growth and introduces eduTDM at Open Science Fair 2019
CORE was active at the Open Science Fair 2019, an international event for all topics related to Open Science. CORE had two posters at this event; a general to the CORE service poster, which updated the community about the full text growth and wide usage of the CORE services, and a second one about the eduTDM.

The eduTDM work aims to provide a central platform to access research articles from multiple repositories at once. This work aims to solve the problem that staff and students affiliated to a university have, when they are trying to access and download research papers their institution subscribes to for text and data mining purposes.
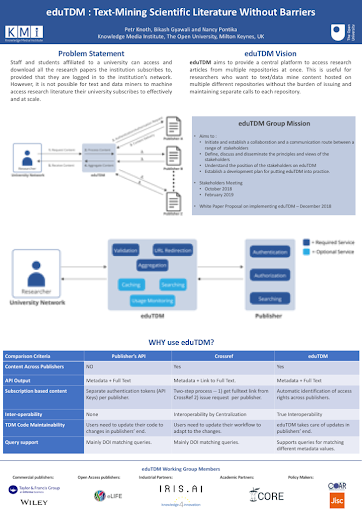
In addition, CORE is part of the FAIR Discovery IN working group, which aims to solve a range of data discovery issues. The group organised a workshop at the OSF2019, where discovery cases were discussed, collected and presented. In this workshop CORE gave a presentation showing the three principles for discovery:
Lesson 1
Argument: The best idea about how to use your data might not be invented by you.
Action: We need programmable access to data.
What has CORE done to help: Widely popular raw data services. CORE API, CORE Dataset and CORE FastSync enabling others to build new applications on top of CORE.
Lesson 2
Argument: Discovery is about adding value where the users are.
Action: Need to bring features to users instead of users to features.
What has CORE done to help: Integration with third party systems and discovery services, e.g. Microsoft Academic, PubMedCentral, institutional repositories, CORE Discovery browser extension, Lean Library, etc.
Lesson 3
Argument: There are different types of discovery use cases.
Action: Develop functionality for a range of discovery use cases
What has CORE done to help: CORE has developed a suite of services:
- CORE Search
- CORE Recommender
- CORE Discovery
- Supporting others
CORE gives an invited talk at the OAI-11 CERN-UNIGE Workshop on Innovations in Scholarly Communications
CORE had an invited presentation at a major conference in Open Access. Petr Knoth was given an opportunity to deliver an invited talk at OAI-11 which was organised by CERN and took place in Geneva, Switzerland. A key outcome of this conference presentation was that Petr Knoth received an invitation from Jean-Claude Burgelman, Head of Open Data Policies and Science Cloud Unit at the European Commissions, DGRTD to give a presentation about CORE at an event the EC is preparing in Brussels.
CORE explores collaboration with the National Institute of Informatics (NII), Tokyo
 Petr Knoth was also invited for a meeting with the National Institute of Informatics (NII), Tokyo, Japan, to discuss collaboration of CORE with NII. The three day meeting of CORE with NII, with the team of Kazu Yamaji, was highly successful and resulted in an identification of a joint work plan that will benefit both CORE and NII and a road map for its implementation, subject to resources in some areas. The potential benefit could be that CORE technology will be used in over 800 of Japanese repositories as well as their national aggregator IRDB. Additionally, CORE might be able to serve as a technology provider for NII on some future projects. The potential work includes:
Petr Knoth was also invited for a meeting with the National Institute of Informatics (NII), Tokyo, Japan, to discuss collaboration of CORE with NII. The three day meeting of CORE with NII, with the team of Kazu Yamaji, was highly successful and resulted in an identification of a joint work plan that will benefit both CORE and NII and a road map for its implementation, subject to resources in some areas. The potential benefit could be that CORE technology will be used in over 800 of Japanese repositories as well as their national aggregator IRDB. Additionally, CORE might be able to serve as a technology provider for NII on some future projects. The potential work includes:
- Enable CORE Recommender in Weko 3 and IRDB
- Enable CORE Discovery in Weko 3
- Work together to deliver and validate (by means of empirically harvesting) a new version of ResourceSync on IRDB which provides On-demand Resource Dumps and, ideally, also a notification functionality via WebSub
- Investigate how CORE can provide full text harvesting and enrichment capabilities for Japanese repositories via IRDB (e.g. full text search, API, etc. )
- Consider joint work/project on delivering analytics dashboard functionality to HEIs (in Japan, UK and beyond)
- CORE to adopt the jpcoar schema, which is widely used by Japanese Repositories.
CORE Statistics
With regards to the CORE statistics for the period July – September 2019
Content: CORE provides access to 24,936,921 free to read full text research papers with currently hosts 13,591,362 full texts hosted directly at CORE. It also provides 135,593,113 searchable research papers.
Data providers: CORE has added 6198 new data providers increasing the content providers to 9,638 in 144 countries.
As CORE does not offer a native Safari Extension for macOS and iOS, please allow me to mention that thanks to the amazing API of CORE my application – Open Access Helper – can serve users on these platforms. It is the dedication of this and other teams, that make this type of app possible – Thank you so much!