 The CORE (COnnecting REpositories) project aims to aggregate open access research outputs from open repositories and open journals, and make them available for dissemination via its search engine. The project indexes metadata records and harvests the full-text of the outputs, provided that they are stored in a PDF format and are openly available. Currently CORE hosts around 24 million open access articles from 5,488 open access journals and 679 repositories.
The CORE (COnnecting REpositories) project aims to aggregate open access research outputs from open repositories and open journals, and make them available for dissemination via its search engine. The project indexes metadata records and harvests the full-text of the outputs, provided that they are stored in a PDF format and are openly available. Currently CORE hosts around 24 million open access articles from 5,488 open access journals and 679 repositories.
Like in any type of partnership, the harvesting process is a two way relationship, were the content provider and the aggregator need to be able to communicate and have a mutual understanding. For a successful harvesting it is recommended that content providers apply the following best practices (some of the following recommendations relate generally to harvesting, while some are CORE specific):
- Platform: For those who haven’t deployed a repository yet, it is highly advised that the repository platform is not built in house, but one of the industry standard platforms is chosen. The benefits of choosing one of the existing platforms is that they provide frequent content updates, constant support and extend repository functionality through plug-ins.
- Repository information status: Check that your repository is included in an international repositories list and that the Open Archives Initiative Metadata Harvesting Protocol (OAI-PMH) address is up to date. The primary directories for CORE are the Directory of Open Access Repositories, the Registry of Open Access Repositories and the Directory of Open Access Journals.
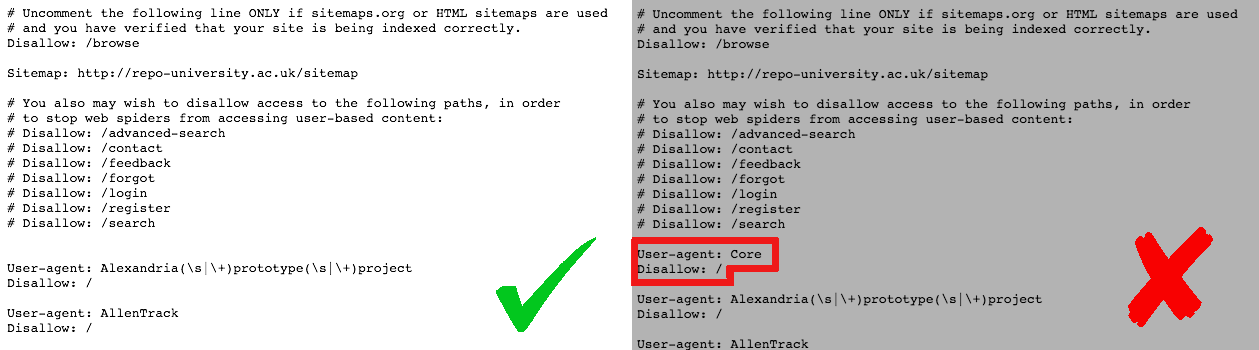
- Robots.txt: This file states whether a web crawler is allowed to access a repository. At CORE often times a harvesting attempt fails from the very beginning due to the fact that the service is banned in this file. Additionally, it is highly recommended that repositories provide equal access levels with the same conditions to all crawlers without making distinctions between services; for example providing complete access at full speed to commercial services, while limiting access to some repository directories or imposing slower crawling speed to non-commercial services. Currently 98 UK research and dissertations repositories are listed in the CORE Dashboard and 10 of these have a prohibiting rule in the robots.txt file for CORE, which affects harvesting.

An example of two robots.txt files and their rules. - Meta-tags: The meta-tags describe a webpage’s content in the code, which makes them extremely useful to machines rather than humans. Crawlers of harvesting services, like CORE, and search engines, like Google Scholar, expect to find a list of meta-tags in the code of each webpage in order to be able to harvest the content properly. Failure to do so results in crawlers making guesses about the content or completely omitting it.
- <dc:identifier> field: The aim of the Dublin Core Metadata tags is to ensure online interoperability of metadata standards. The importance of the <dc:identifier> tag is that it describes the resource of the harvested output. CORE expects in this field to find the direct URL of the PDF. When the information in this field is not presented properly, the CORE crawler needs to crawl for the PDF and the success of finding it cannot be guaranteed. This also causes additional server processing time and bandwidth both for the harvester and the hosting institution.
There are also three additional points that need to be considered with regards to the <dc:identifier>; a) this field should describe an absolute path to the file, b) it should contain an appropriate file name extension, for example “.pdf” and c) the full-text items should be stored under the same repository domain.
A <dc:identifier> tag including all three requirements - URL external resolving: When external resolution services, such as Handle.Net® or doi®, are used it is important to ensure that the URL produced works properly and it links to an actual document and not a dead page.
- Is everything in order?: To ensure that everything is alright with your repository, use monitor tools to check how your repository looks to the outside world. Such tools are the OAI PMH validator, which will test your endpoint, the Google Webmaster Tools, which will help improve your search rank and the CORE Dashboard, which provides detailed information on the harvesting process, technical issues and how to improve the exposure of your metadata.

If we compare web crawling to harvesting, the latter is more helpful to repositories since it deals with structured XML formats that contain all the bibliographic information fields. That way all this data can be reused for data analysis and data mining purposes.
* I would like to thank the CORE developers, Samuel Pearce, Lucas Anastasiou and Matteo Cancellieri for their technical input in this blog post.
Re #5, there seems to be quite differing practices re whether to use the dc:identifier or dc:relation field for PDFs attached to records. In my own organisation’s repo, and in several others I’ve just checked (all using different repo software), it appears that the dc:relation field is commonly used; although I did find some that use dc:identifier.
We are aware that institutions apply different practices, this is why we decided to mention this point in this blogpost. According to OpenAIRE and RIOXX specifications, the dc:identifier must be an HTTP URI that points to a related source and/or identifiers such as a DOI or an ISBN. The dc:relation field describes objects that relate to the item described in the dc:identifier – that could be for example a dataset, but not the PDF itself. My last point is CORE specific only, and this is that CORE downloads and follows PDFs that are linked to from the dc:identifier tag only.