We are happy to announce the release of CORE Reader, which provides a seamless experience for users wishing to read papers hosted by CORE. In this post, we provide an overview of what is new and we encourage you to follow this development as new functionalities in the reader are on our roadmap.

At the beginning of this project, there was a reflection that most open access services do not yet provide a rich user experience for reading research papers. Determined to change this, we originally started looking at whether CORE could render research papers as HTML, as has recently become trendy across publisher platforms. While such rendering remains to be one of the ultimate goals, we realised that this could only be achieved for a small fraction of documents in CORE. More specifically, those that the data provider offers in machine readable formats, such as LaTeX or JATS XML. While we want to encourage more repositories to support such formats (and this remains to be a Plan S recommendation), we wanted to improve the reading experience for all of our users across all of our content.
To achieve this goal we had to completely rethink and redesign the previously provided Reader. Our key considerations were also related to our analysis of user flow and behaviour across CORE. Specifically, we recognise that the objective of most people is to get access to the full text of the research paper as quickly as possible and this is where the users should be supported
CORE Reader is a free web application that can be used by everyone. It is supported on desktop, laptop and mobile devices of any operating system and runs in any browser.
Some of the new features we have added are shown below.
Transparent document navigation
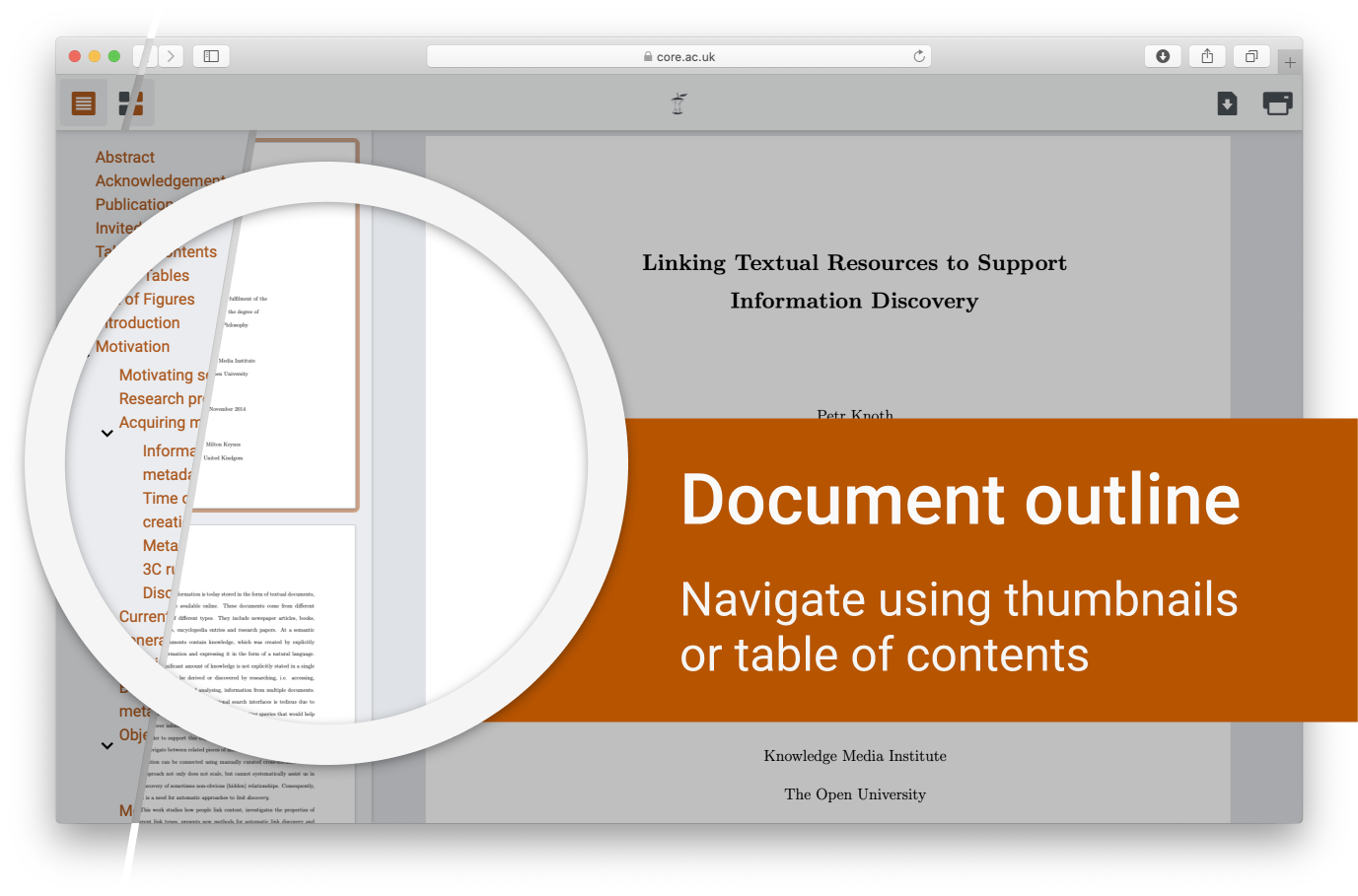
Among the new features, users can see two new buttons at the top left corner. The left one helps to navigate through the paper’s Outline (the outline is available for PDFs that support it). The right one displays Thumbnails, enabling the user to go through the preview of PDF pages and navigate them faster.
Related papers
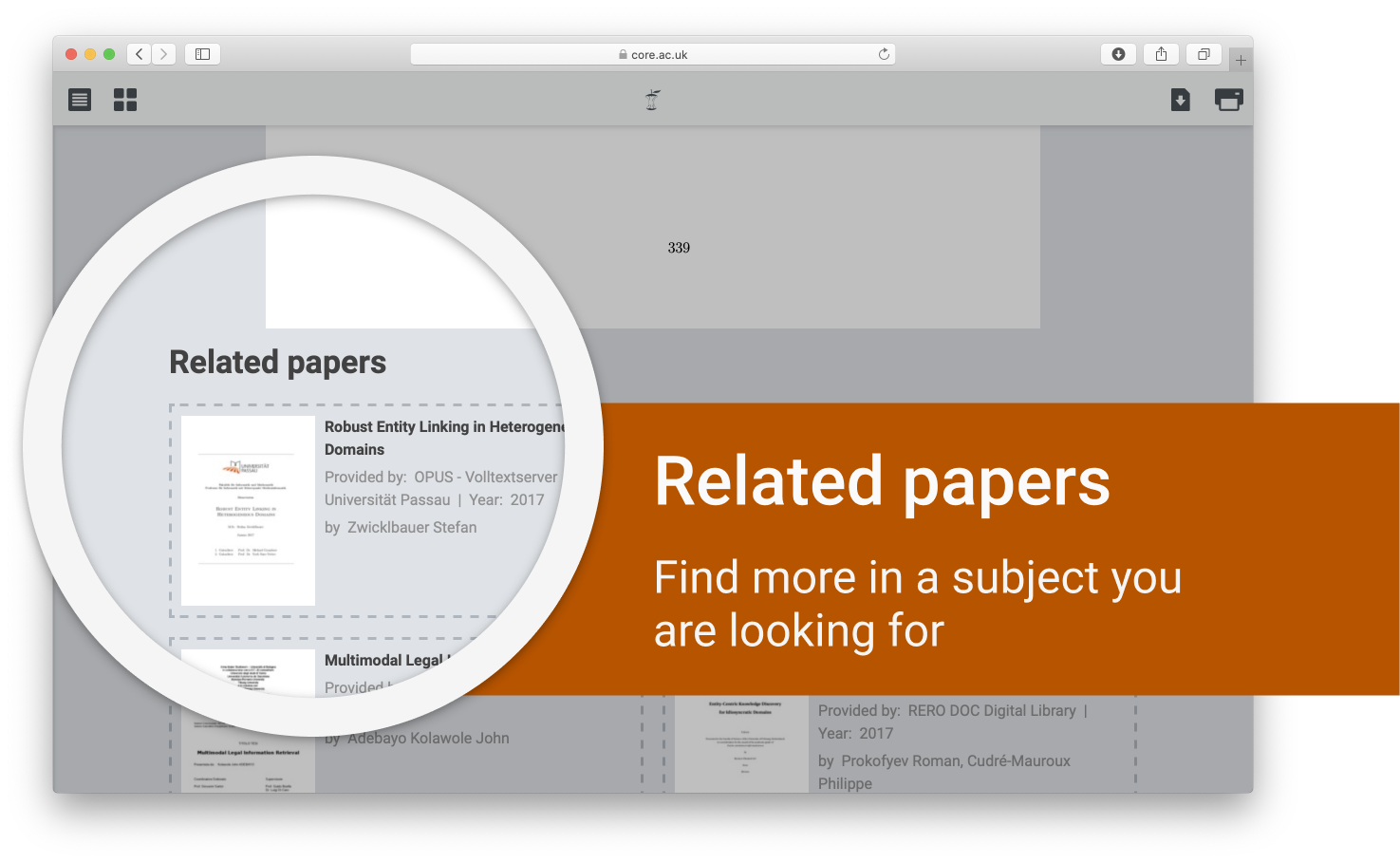
The Reader also has the functionality of the CORE Recommender integrated. This enables users to discover papers similar to their interest articles from across the network of thousands of open access data providers.
Overall, the new Reader simplifies viewing full texts of research papers by:
- harmonising the UI of the Reader with the rest of the CORE website;
- integrating CORE functionality including the Recommender directly into a PDF viewer.
In the near future, we will start redirecting users coming to CORE from external systems, including search engines, to this enhanced view of the document.
Importantly, we have plans for a number of new functionalities improving the way our users access, read, navigate and organise knowledge in research papers. We want to start integrating these functionalities in the Reader in the future.
Dr Petr Knoth, Head of CORE and Senior Research Fellow in Text and Data Mining at the Open University says: “This technology will rely on artificial intelligence. More specifically, we are putting our resources in training machine learning models to parse and locate relevant information in the research papers as well as to link relevant information from external sources. We are then working with our UX experts to learn how best to integrate the output from these models into new tools to provide an improved user experience. We always wanted to do this, but as we did not have the Reader, there was no place for us to make such functionality available. The deployment of the Reader opens the door to many new exciting possibilities.” But as we cannot say too much at this stage, please stay tuned!
We also take this opportunity to reach out to other researchers in the area of text mining scientific papers to get in touch with us if they are interested in trying and evaluating their tools from within the CORE Reader.
Finally, the CORE Reader is open source and we are putting together plans on how to make it available to our data providers to deploy directly in their systems. We left this announcement for the end as we thought that this global community of repositories might find this particularly exciting.
One thought on “CORE users can now read articles directly on our site”
Comments are closed.