CORE has been working closely with our member institutions to co-create the design and functionality for a new module that can assist with the discovery and management of authors’ Rights Retention statements for published works.
The problem
A Rights Retention Statement is a declaration by an author that they retain certain copyright rights to their scholarly work, even when they sign a publication agreement with a journal publisher. This statement is often used to ensure that authors can comply with open access mandates from funding agencies, such as those under Plan S, which require that the research they fund be made freely available to the public. Under Plan S, the Rights Retention strategy is a significant aspect because it aims to ensure that authors retain copyright on their articles, even when they publish in subscription journals.
Numerous benefits for authors, institutions, funders and other stakeholders when a well-managed Rights Retention strategy is employed have been reported, including:
- Ensures Open Access: Authors can make their accepted manuscripts immediately available upon publication, regardless of the subscription status of the journal.
- Compliance with Funders’ Mandates: Authors can comply with the open access mandates of their research funders by including a Rights Retention Statement in their papers, ensuring that the terms of their funding are met.
- Retention of Copyright: The statement typically ensures that authors retain the copyright to their work, rather than transferring it entirely to the journal publisher. This means authors can control the reuse and distribution of their work.
- Control over Scholarly Use: Authors can allow their works to be used for scholarly and educational purposes without restriction, which can facilitate academic discussion and the dissemination of knowledge.
- Wide Dissemination: It allows for wider dissemination of the research as there are no paywall restrictions, thereby increasing the reach and potential impact of the work.
- Promotion of Equity: By allowing for broader access, it supports the goal of equitable access to research findings. This is particularly important for researchers from low-income countries or institutions that cannot afford expensive journal subscriptions.
- Facilitation of Text and Data Mining: Open Access enables text and data mining (TDM), which is crucial for contemporary research practices, including meta-analyses and the development of AI and machine learning models.
There are, however, some significant hurdles to the management and capturing of Rights Retention Statements as a standard part of the metadata associated with an academic article. Specifically, this information is needed for the rights management within a repository and might also be needed for monitoring OA compliance. Adding this information manually is clearly no small task.
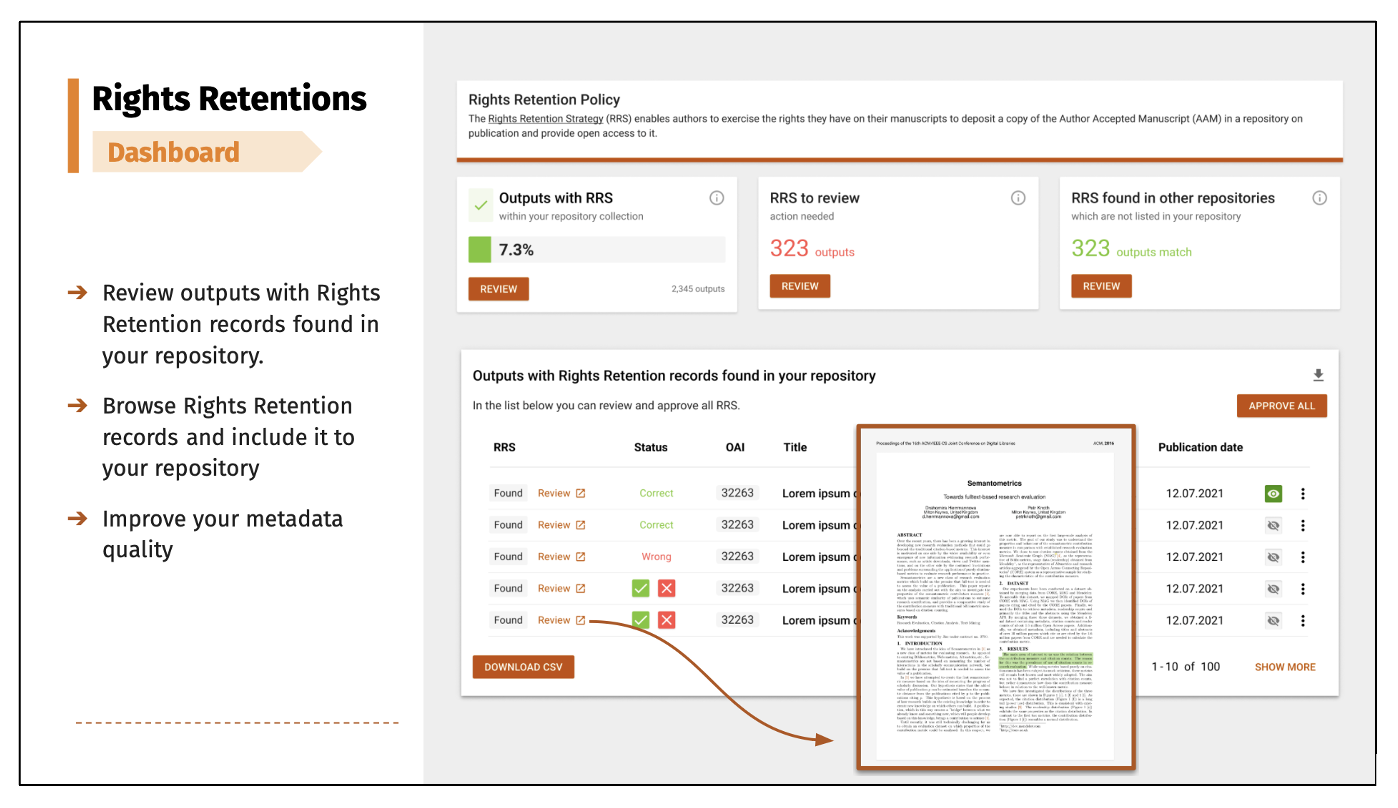
Figure 1: Wireframe design for the new CORE Dashboard Rights Retention module
Proposed solution
The co-creation process undertaken with CORE member institutions has enabled us to identify two distinct areas in which CORE can aid repositories with this workflow;
Post-deposit
CORE contains a constantly growing collection that currently runs to over 35 million full text articles from over 12,000 repositories globally. Many of these articles contain Rights Retention Statements that have not been identified during the deposit process and are therefore not part of the articles’ metadata. In fact, at this point in time, we are aware that not all repository software provides support for capturing information about Rights Retention Statements. However, given the fact that this is critically important for rights management and OA compliance with funder mandates, we anticipate that this support will become increasingly common.
CORE is currently designing a new module that leverages a machine learning (ML) model for the automatic identification and extraction of Rights Retention Statements from full text articles. This will simplify the process for encoding this information in the metadata. We are now finalising the development of this functionality as a CORE Dashboard module that member institutions will be able to use to benefit from this new source of information.
At point of deposit
While the post-deposit identification of Rights Retention Statements is close to its release, we have recognised, after discussions with several institutions, that it would be ideal, for new publications, to integrate the Rights Retention Statements identification with the article deposit workflow.
Currently, when a repository manager is creating or reviewing a new submission, a check for a Rights Retention Statement within the article must be completed and then this new information must then be added manually to the metadata for the submission. This is a long-winded and cumbersome process which increases the burden on repository managers, introduces the potential for inaccuracies and lessens the likelihood of widespread availability of Rights Retention Statements.
Instead, it would be possible to call the new Rights Retention Statements identification tool over its API from the repository software at the point of deposit. In this way, the PDF of the author’s manuscript can be analysed and the Rights Retention Statement, if present, can be automatically extracted and then validated by the depositor. This extracted data can then become part of the metadata record, thus reducing the manual burden on repository staff and improving the consistency in capturing this information. We are currently in discussions with repository software providers to develop this integrated functionality.
Closer integration of CORE services with repository software has long been a goal for us and will enable us to hugely improve the value of the data that CORE can provide to repositories. Additionally, there is often other information present in a manuscript which is not currently included in the metadata, such as data access statements or funder acknowledgements. The framework described here for identifying and extracting Rights Retention Statements can also be extended to encompass this other data which can then be added to a repository’s records, enhancing both the quality of the metadata and its overall value.
If you are interested in learning more about this process and would like to provide feedback on the above-described workflow, then we would be very interested in hearing from you. We would be also happy to demonstrate the functionality to repositories that would like to be further involved in the development process. If your institution is not already a member of CORE, take a look at the different options available on our members page. We keep all our members up to date with regular progress reports and we welcome input from members on our development roadmap.