* This post was authored by Matteo Cancellieri, Petr Knoth and Nancy Pontika.
Last month, CORE attended the JISC ORCID hackday events in Birmingham and London. (ORCID is a non-profit organisation that aims to solve the author disambiguation problem by offering unique author identifiers). Following the discussions that sparked off at the two events, we decided to test the CORE data towards ORCID’s API and we discovered some information that we think is of interest to the scholarly community.
Currently, CORE has data for 5.5 million unique Document Object Identifiers (DOIs) linked to records in our database (both metadata only and full text). Based on this number, we wanted to find out how many of these DOIs were connected to an ORCID id. Therefore, we set up a script that called the ORCID API obeying to the rate limit. In around 7 days we had collected the full results.
From the 5,523,577 articles with a DOI that existed in the CORE collection, we discovered that 196,713 different authors had an ORCID id, and 927,645 articles included at list one ORCID id.

We found that 16% of the DOIs in CORE are connected to at least one author registered in ORCID. The following map shows the distribution of the ORCID ids discovered across the world.
Why is this useful? It enables us to assess the ORCID’s coverage across a large multidisciplinary dataset of Open Access papers. Doing some more digging in the data (we haven’t done this yet), it would also be possible to analyse the growth of ORCID over time. These data can be sliced and diced according to various criteria, such as geographical coverage or repository, to understand how ORCID coverage can be improved.
Based on our results, the UK has the biggest number of ORCID IDs. However, this result is a bit skewed by the fact that CORE has an excellent content coverage across UK repositories.
We also tried to find authors with ORCID IDs who deposited content in one of the UK repositories. Our result indicates that 68,849 ORCIDs were discovered from 254,467 unique DOIs. It was then very useful to look at the distribution of the top 15 repositories based on ORCID IDs across the UK repositories. This analysis can be extremely helpful in identifying repositories with low ORCID coverage and encouraging them to take an appropriate action.

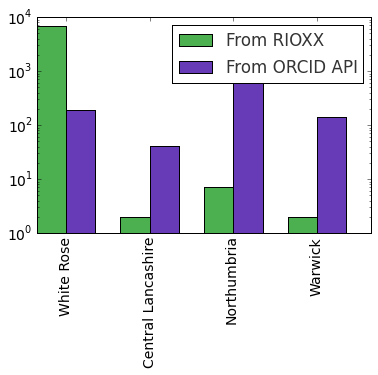
Repositories implementing RIOXX have already the possibility to expose ORCID IDs through an attribute in the rioxxterm:author tag. While this opportunity exists, our quick survey showed that only few repositories supporting RIOXX have implemented it. Thanks to John Salter, Software Developer at Leeds University, for his help in collecting the data and creating the chart. John is currently working on including the ORCID IDs in the White Rose repository, which “forced” us 🙂 to use a log-scale in the chart due to the widespread implementation of the ID attribute in their metadata (>6k ORCID IDs vs less than 10 IDs from the other repositories)
Highlights
Dataset
We have made the dataset available online on Github and it can be found here .
There are few caveats in the data that must be taken into consideration. Our main challenge was that some of the aggregated DOIs were not valid or pointing to a journal instead of a paper. The ORCID API returned only a partial match and in the case of the journals’ DOIs, this meant that the ORCID IDs returned results that regarded all the authors of one journal instead of one specific paper.
What next?
In this preliminary study we realised that the information we extracted from the data was useful to us and, perhaps, could be useful to repository managers. Our plan is to design and implement a new functionality in the CORE Repositories Dashboard. We are planning to submit a proposal for this to OR2017 and we would really appreciate your feedback. If you are a repository manager and you want to know more, contact us.
This is really interesting work – it feels like the first real benefits of joined up systems sharing joint identifiers are starting to show themselves here!
I was amazed by the lack of ORCIDs coming through the RIOXX harvest. I think it highlights an area where repositories might need a bit of a health-check.
If you’ve got loads of useful identifiers in your system, but you’re not exposing them over OAI-PMH, you might need to get your geek on!
If you:
– have an EPrints repository
– have the RIOXX extension installed
– have ORCIDs in your repository
then the details here: https://wiki.eprints.org/w/ORCID#Exposing_the_ORCID_in_RIOXX may be of use to you!