We recently held the inaugural meeting of the CORE Board of Supporters where we were joined by 32 representatives from the organisations that have committed to supporting the ongoing sustainability of CORE by joining our membership program.
These amazing institutions are critical to the survival of CORE and we’re incredibly grateful for the support they provide us.

Current CORE members
We work with our members as part of our commitment to The Principles of Open Scholarly Infrastructure (POSI), by listening to our members we can understand precisely what is most important to them. Prior to this kickoff meeting, we therefore sent a wide-ranging survey to gauge what really matters to our members’ repositories, their users and the staff that manage them.
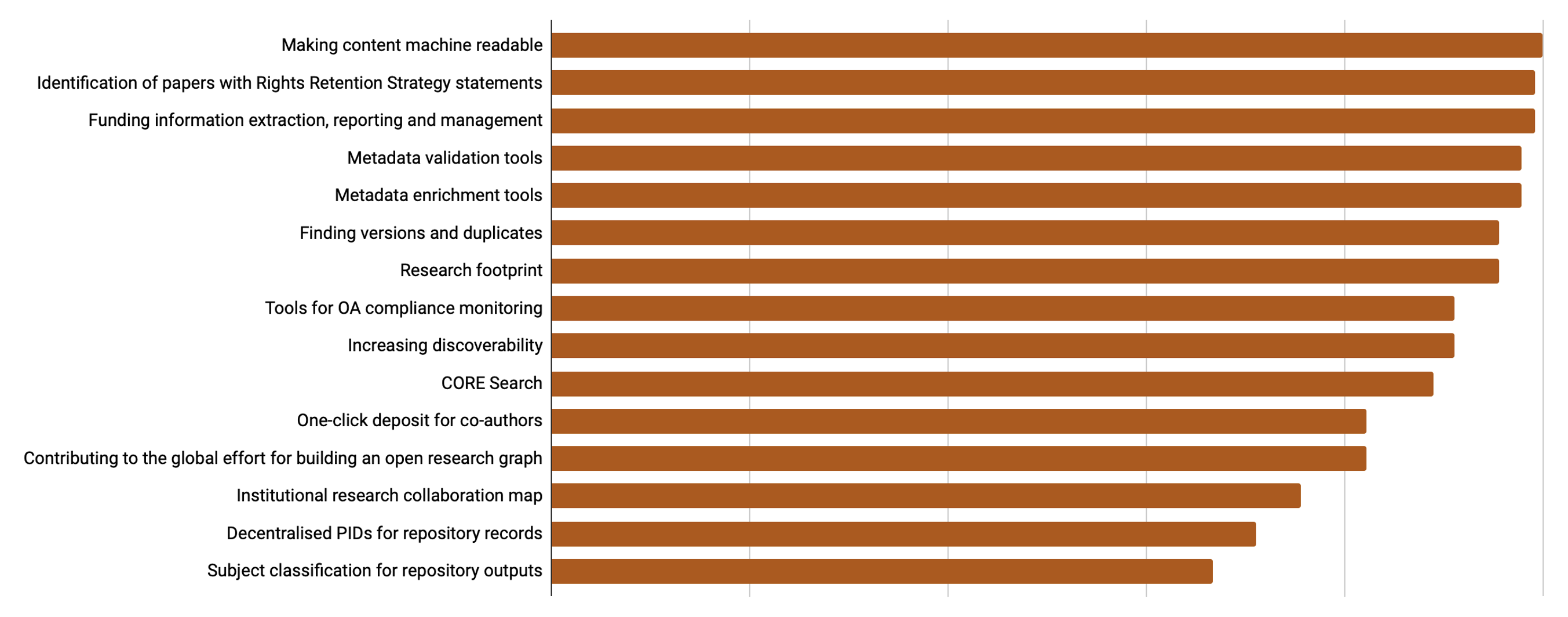
What our members say is important to them.
Respondents were asked how CORE can best work with them, and the types of services and support that CORE could provide that would have the most impact. We received a fantastic range of responses and the next round of feedback will provide our members the opportunity to decide which of the features shown above will be the focus of our roadmap for the coming months.
Metadata validation and enrichment scored highly for many institutions, whilst identifying funding information and rights-retention statements were also highly important. Just out in front however, was making repository content machine-readable which was rated as highly important by almost all respondents. Overall, the push towards machine-readable scholarly documents is part of a broader trend towards digitisation and automation in science and knowledge production more generally. Additionally, it is seen as essential for handling the increasing volume and complexity of scientific literature. Indeed, in the U.S., the recent OSPT memo on ‘Ensuring Free, Immediate, and Equitable Access to Federally Funded Research‘ includes machine-readability as a required component of the archiving and deposition of federally funded research.
When scholarly documents are machine-readable, this simplifies many tasks, and enables analyses and research that would otherwise not be possible;
- Data Mining and Text Analysis: Machine-readable documents allow researchers and analysts to perform text mining or data analysis at scale. Researchers can examine trends, patterns, and relationships that would be nearly impossible to find manually. For example, one could identify emerging themes across thousands of papers or track the evolution of a research topic over time.
- Interoperability: Machine-readable documents can be more easily shared and integrated with other systems. For example, a citation database could automatically pull citation information from machine-readable documents, ensuring that all references are accurately and consistently recorded.
- Semantic Web and Linked Data: Making documents machine-readable enables the creation of semantic web applications and linked data, where information from different sources can be connected and explored in new ways.
- Accessibility: Machine-readable documents can be easily accessed, analysed, and searched by computer programs. This is crucial for individuals who rely on assistive technologies like screen readers to access information.
- Open Science and Reproducibility: In the context of open science, machine-readable formats are hugely helpful as they allow others to verify and reproduce research findings more easily. This supports the broader scientific goal of transparency and reproducibility.
We’re really grateful to everyone who provided feedback via the survey and we’re now working on a follow up to this post with a deeper dive into some of the features listed above. We have some really exciting things in the pipeline that we’re looking forward to sharing with you all.