This blog post was originally posted at the arXiv blog.

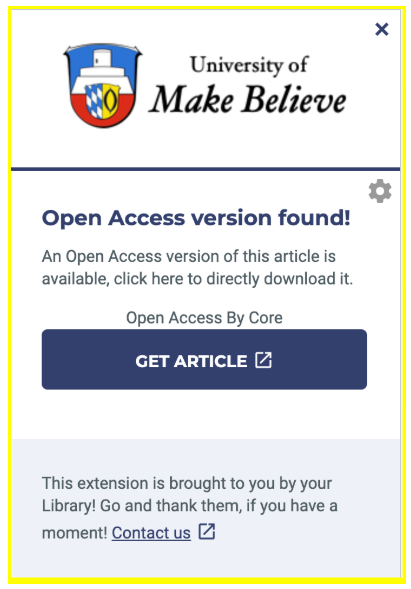
arXiv readers now have a faster way to find articles relevant to their interests. From an article abstract page, readers can simply activate the CORE Recommender to find additional open access research on similar topics.
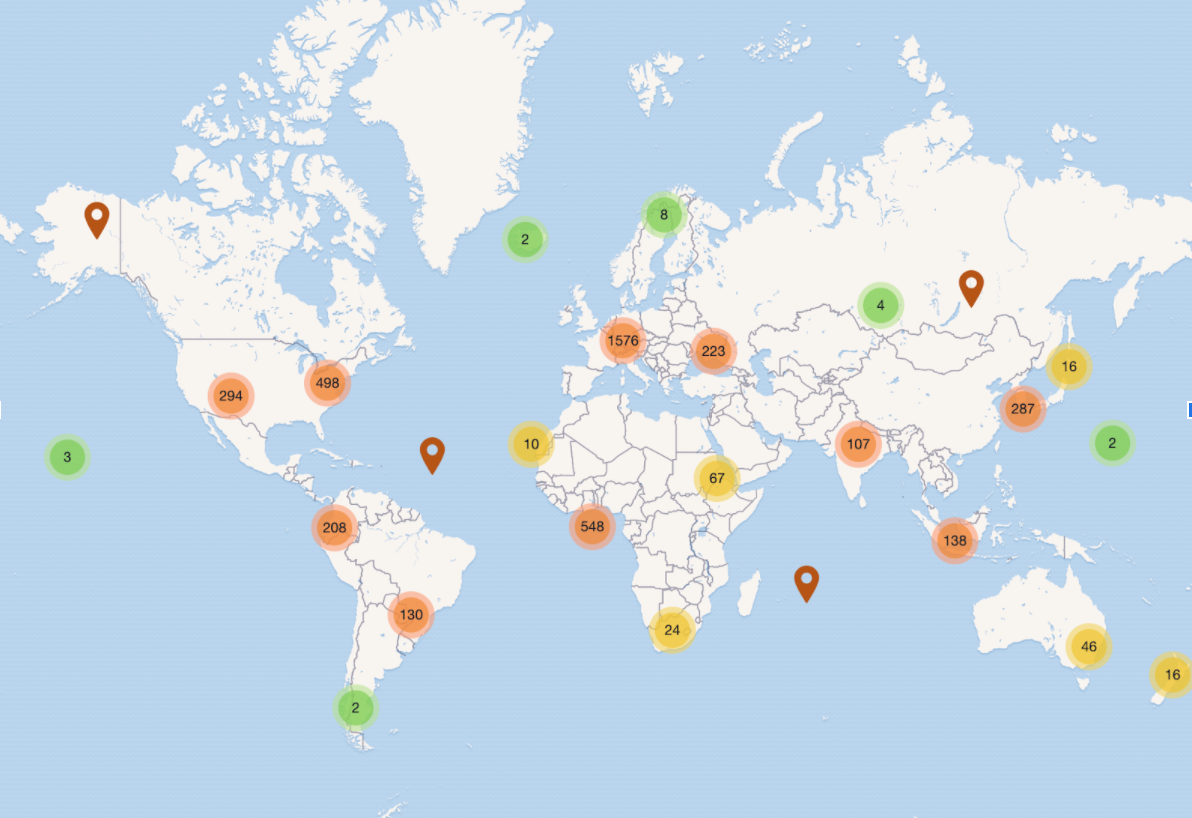
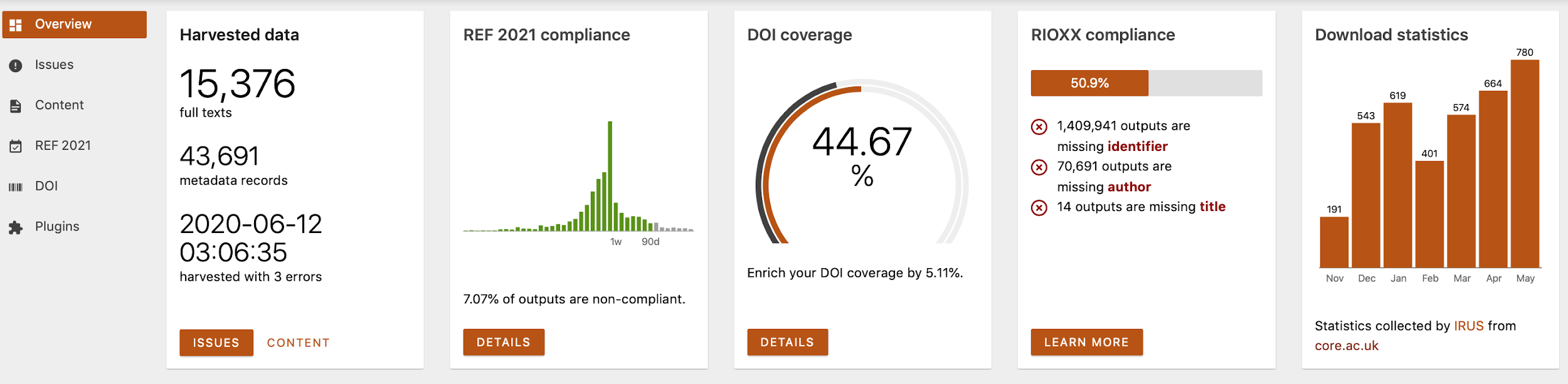
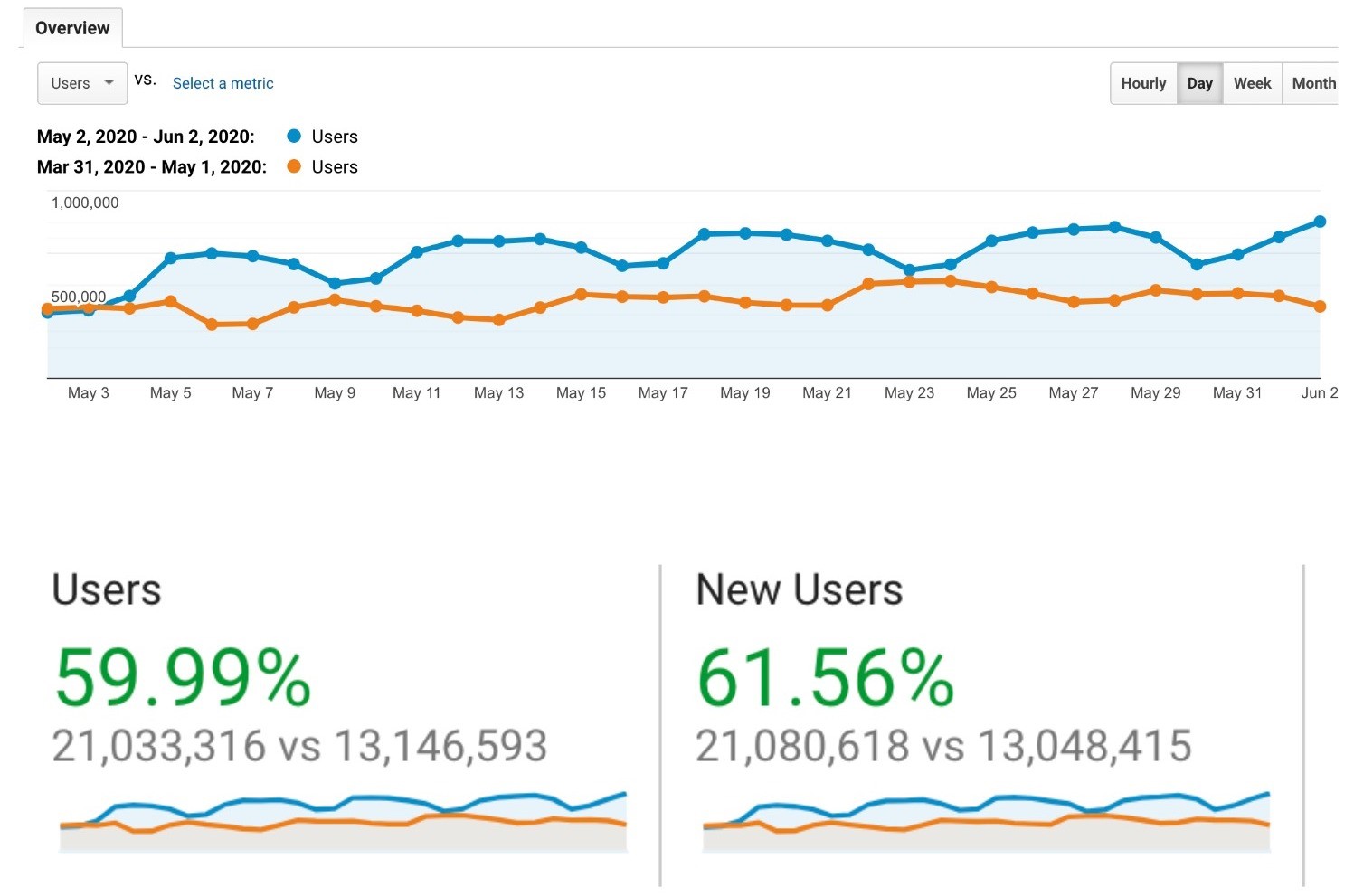
The Recommender, part of the arXivLabs toolset, was developed by CORE, a global aggregator of open access scientific content, which provides access to millions of full texts. CORE’s mission is to aggregate all open access research outputs from repositories and journals worldwide and make them available to the public. In this way, CORE facilitates free unrestricted access to research for all.