On October 23rd, The Open University held the Research Excellence Awards 2019 Ceremony. CORE was presented with the award for “Outstanding Impact of Research on Society and Prosperity” This important award reflects the clear value CORE represents to its users. You can read more about the ceremony and the award at the KMi Planet News.
CORE releases CORE Discovery in Mozilla and Opera browsers
CORE Discovery, a browser extension that offers one-click access to free copies of research papers whenever you might hit a paywall, is now published in Mozilla and Opera Stores. The plug in was originally released as a Google Chrome extension.
CORE presents its full texts growth and introduces eduTDM at Open Science Fair 2019
CORE was active at the Open Science Fair 2019, an international event for all topics related to Open Science. CORE had two posters at this event; a general to the CORE service poster, which updated the community about the full text growth and wide usage of the CORE services, and a second one about the eduTDM.read more...
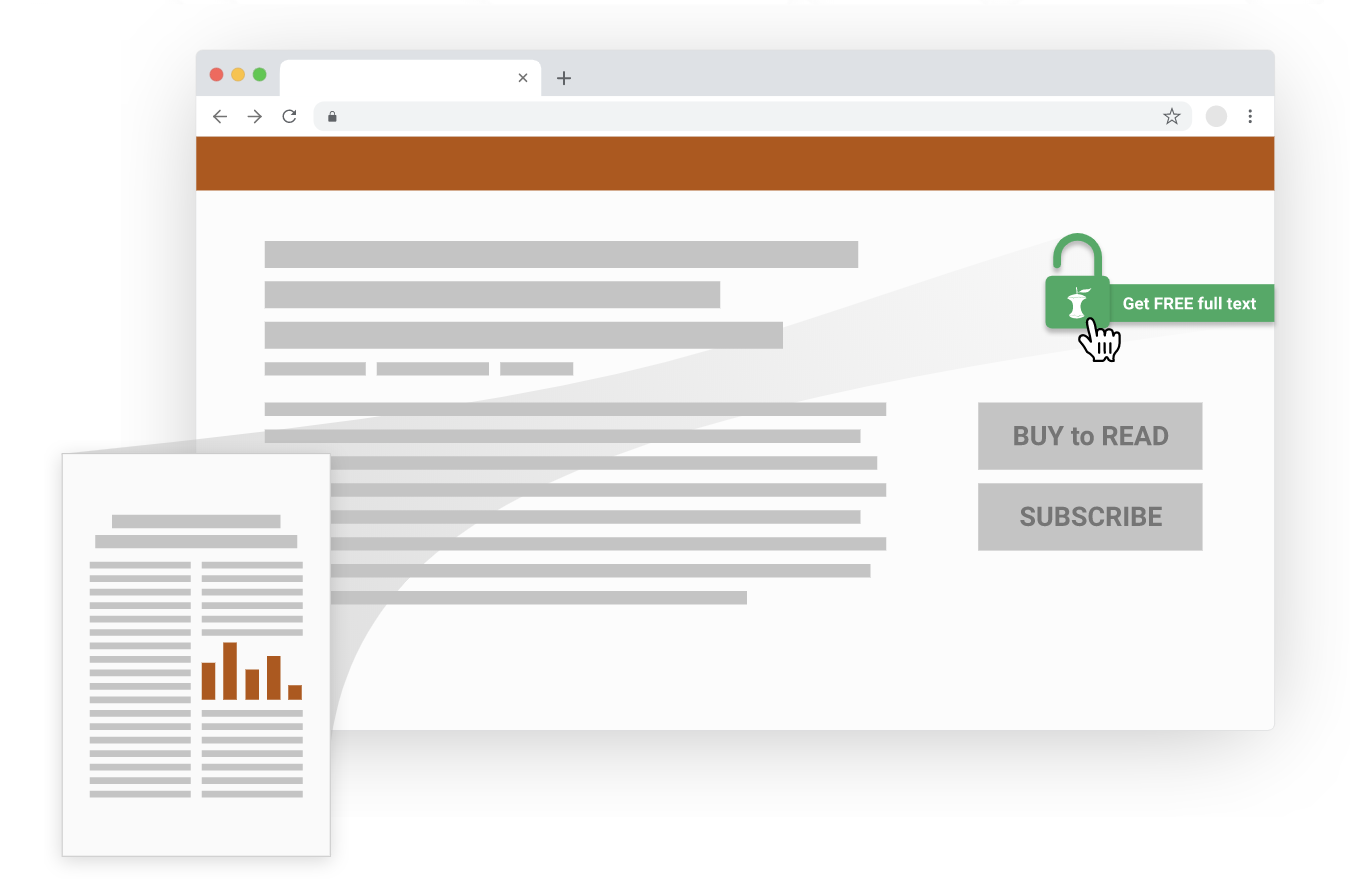
CORE has released a BETA version of the CORE Discovery tool, which offers a one-click access to free copies of research papers whenever you might hit a paywall.
Our free CORE Discovery service provides you with:
Highest coverage of freely available content. Our tests have shown CORE Discovery finding more free content than any other discovery system.
Free service for researchers by researchers. CORE Discovery is the only free content discovery extension developed by researchers for researchers. There is no major publisher or enterprise controlling and profiting from your usage data.
Best grip on open repository content. Due to CORE being a leader in harvesting open access literature, CORE Discovery has the best grip on open content from open repositories as opposed to other services that disproportionately focus only on content indexed in major commercial databases.
Repository integration and discovering documents without a DOI. The only service offering seamless and free integration into repositories. CORE Discovery is also the only discovery system that can locate scientific content even for items with an unknown DOI or which do not have a DOI.
The tool is available as:
A browser extension for researchers and anyone interested in reading scientific documents
Plugin for repositories, enriching metadata only pages in repositories with links to freely available copies of the paper
API for developers and third party services
If you are interested in the CORE Discovery plugin do get in touch.
CORE receives Vannevar Bush Best Paper Award
The CORE team has also won the Vannevar Bush Best Paper Award at JCDL 2019, one of the most highly recognised digital libraries conference in the world, for our work on analysing how soon authors deposit into repositories, which was driven by CORE data. A blog post about this is already available. read more...
This was another productive year for the CORE team; our content providers have increased, along with our metadata and full text records. This makes CORE the world’s largest open access aggregator
. More specifically, over the last 3 months CORE had more than 25 million users, tripling our usage compared to 2017. According to read more...
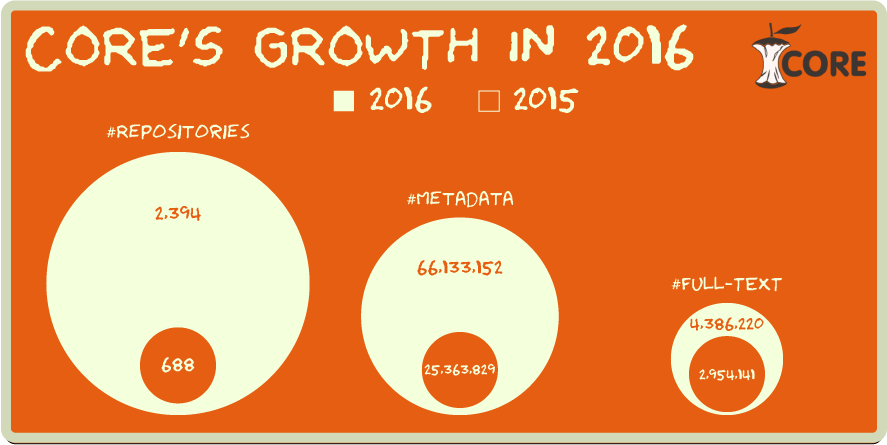
For yet another year (see previous years 2016, 2015) CORE has been really productive; the number of our content providers has increased and we have now more open access full text and metadata records than ever.
Our services are also growing steadily and we would like to thank the community for using the CORE API and CORE Datasets.
CORE is continuously growing. This month we have reached 75 million metadata and 6 million full of text scientific research articles harvested from both open access journals and repositories. This past February we reported 66 million metadata and 5 million full text articles, while at the end of December 2016 we had just over 4 million full text. This shows our continuous commitment to bring to our users the widest possible range of Open Access articles.
To celebrate this milestone, we gathered the knowledge of our data scientists, programmers, researchers, and designers to illustrate our portion of metadata and full text with a less traditional (sour apple) “pie chart”. read more...
. It is a pleasure to see CORE listed as Number 1 resource in this list. CORE has been included in this list thanks to its large volume of open access and free of cost content, offering 66 million of bibliographic metadata records and 5 million of full-text research outputs. Our content originates from open access journals and repositories, both institutional and disciplinary and can be accessed via our read more...
CORE is thrilled to announce that it currently provides 5 millions of open access full-text papers.
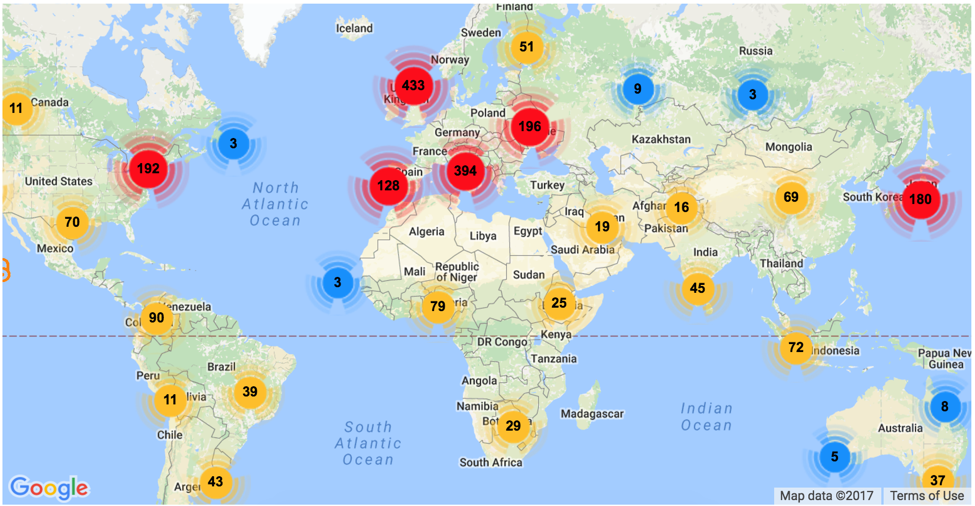
CORE’s data providers from around the world
“In the last year, we have managed to scale up our harvesting process. This enabled us to significantly increase the amount of open access content we can offer to our users. With more and more open access content being made available by data providers, thanks to recent open access policies, CORE now also captures and provides access to a higher percentage of global research literature ”, says CORE’s founder, Dr Petr Knoth.
With 66 million metadata records and 5 million full-text, from 102 countries, in 52 different languages, CORE becomes now the world’s largest full-text open access aggregator. CORE embraces the vibrant collections of both institutional and disciplinary repositories, while its large volume of scholarly outputs ranges from scientific research papers, to grey literature and from Master’s to Doctoral thesis. In addition, it is a metasearch for the all the open access peer-reviewed scientific journal articles published in open access journals. read more...
The past year has been productive for the CORE team; the number of harvested repositories and our open access content, both in metadata and full-text, has massively increased. (You can see last year’s blog post with our 2015 achievements in numbers here.)
There was also progress with regards to our services; the number of our API users was almost doubled in 2016, we have now about 200 registered CORE Dashboard users, and this past October we released a new version of our recommender and updated our dataset.
Around this time of the year, the joyful Christmas spirit of the CORE team increases along with our numbers. Thus, we decided to recalculate how far are the CORE research outputs – if we had printed them – from reaching the moon (last year we made it to 1/3 of the way).
We are thrilled to see that this year we got CORE even closer to the moon! We would also like to thank all our data providers, who have helped us reaching this goal.
Fear not, we will never print all our research outputs, we believe that their mission is to be discoverable on the web as open access. Plus we love trees.
Merry Christmas from the CORE Team!
* Note: Special thanks to Matteo Cancellieri for creating the CORE graphics.
=&0=&This post was authored by Nancy Pontika, Lucas Anastasiou and Petr Knoth.
The CORE team is thrilled to announce the release of a new version of our recommender; a plugin that can be installed in repositories and journal systems to suggest similar articles. This is a great opportunity to improve the functionality of repositories by unleashing the power of recommendation over a huge collection of open-access documents, currently 37 million metadata records and more than 4 million full-text, available in CORE.
Highlights
Recommender systems and the CORE Plug-In
Typically, a recommender tracks a user’s preferences when browsing a website and then filters the user’s choices suggesting similar or related items. For example, if I am looking for computer components at Amazon, then the service might send me emails suggesting various computer components. Amazon is one of the pioneers of recommenders in the industry being one of the first adopters of item-item collaborative filtering (a method firstly introduced in 2001 by Sarwar et al. in a highly influential scientific paper of modern computer science).
Over the years, many recommendation methods and their variations have been suggested, evaluated both by academia and industry. From a user’s perspective, recommenders are either personalised, recommendations targeted to a particular user, based on the knowledge of the user’s preferences or past activity, or non-personalised, recommending the same items to every user.
From a technological perspective, there are two important classes of recommender systems: collaborative filtering and content based filtering.
1. Collaborative filtering (CF):
Techniques in this category try to match a user’s expected behaviour over an item according to what other users have done in the past. It starts by analysing a large amount of user interactions, ratings, visits and other sources of behaviour and then builds a model according to these. It then predicts a user’s behaviour according to what other similar users – neighbour users – have done in the past – user-based collaborative filtering.
The basic assumption of CF is that a user might like an unseen item, if it is liked by other users similar to him/her. In a production system, the recommender output can then be described as, for example, ‘people similar to you also liked these items.’
These techniques are now widely used and have proven extremely effective exploratory browsing and hence boost sales. However, in order to work effectively, they need to build a sufficiently fine-grained model providing specific recommendations and, thus, they require a large amount of user-generated data. One of the consequences of insufficient amount of data is that CF cannot recommend items that no user has acted upon yet, the so called cold-items. Therefore, the strategy of many recommender systems is to expose these items to users in some way, for example either by blending them discretely to a home page, or by applying content-based filtering on them decreasing in such way the number of cold-items in the database.
While CF can achieve state-of-the-art quality recommendations, it requires some sort of a user profile to produce recommendations. It is therefore more challenging to apply it on websites that do not require a user sign-on, such as CORE.
2. Content-based filtering (CBF)
CBF attempts to find related items based on attributes (features) of each item. These attributes could be, for example the item’s name, description, dimensions, price, location, and so on.
For example, if you are looking in an online store for a TV, the store can recommend other TVs that are close to the price, screen size, and could also be similar – or the same – brand, that you are looking for, be high-definition, etc. The advantage of content-based recommendations is that they do not suffer from the cold-start problem described above. The advantage of content-based filtering is that it can be easily used for both personalised and non-personalised recommendations.
The CORE recommendation system
There is a plethora of recommenders out there serving a broad range of purposes. At CORE, a service that provides access to millions of research articles, we need to support users in finding articles relevant to what they read. As a result, we have developed the CORE Recommender. This recommender is deployed within the CORE system to suggest relevant documents to the ones currently visited.
In addition, we also have a recommender plugin that can be installed and integrated into a repository system, for example, EPrints. When a repository user views an article page within the repository, the plugin sends to CORE information about the visited item. This can include the item’s identifier and, when possible, its metadata. CORE then replies back to the repository system and embeds a list of suggested articles for reading. These actions are generated by the CORE recommendation algorithm.
How does the CORE recommender algorithm work?
Based on the fact that the CORE corpus is a large database of documents that mainly have text, we apply content-based filtering to produce the list of suggested items. In order to discover semantic relatedness between the articles in our collection, we represent this content in a vector space representation, i.e. we transform the content to a set of term vectors and we find similar documents by finding similar vectors.
The CORE Recommender is deployed in various locations, such as on the CORE Portal and in various institutional repositories and journals. From these places, the recommender algorithm receives information as input, such as the identifier, title, authors, abstract, year, source url, etc. In addition, we try to enrich these attributes with additional available data, such as citation counts, number of downloads, whether the full-text available is available in CORE, and more related information. All these form the set of features that are used to find the closest document in the CORE corpus.
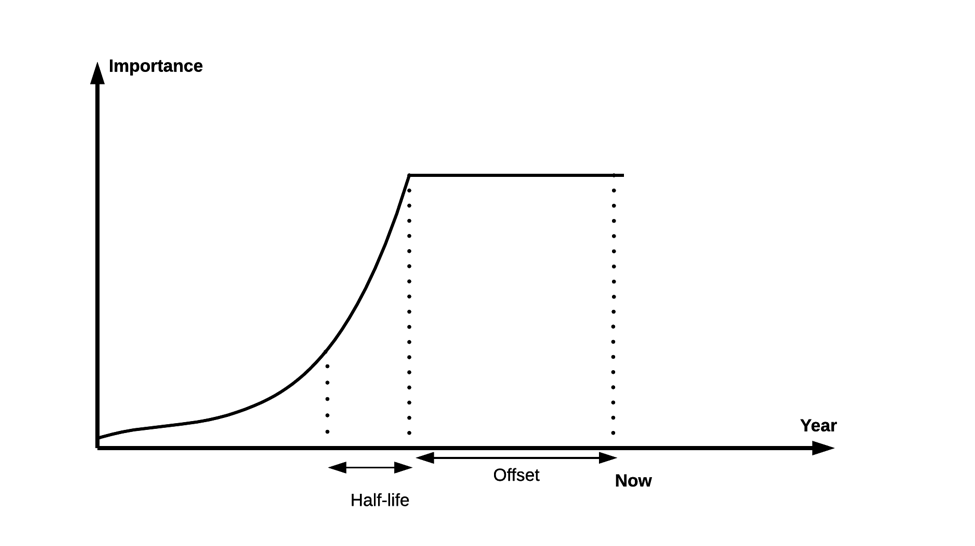
Of course not every attribute has the same importance as others. In our internal ranking algorithm we boost positively or negatively some attributes, which means that we weigh more or less some fields to achieve better recommendations. In the case of the year attribute, we go even further, and apply a decay function over it, i.e. recent articles or articles published a couple of years ago get the same boosting (offset), while we reduce the importance of older articles by 50% every N years (half-life). In this way recent articles retain their importance, while older articles contribute less to the recommendation results.
Decay function in year attribute
Someone may ask:
how do you know which weight to put in each field you are using? How did you come up with the parameters used in the decay function?read more...
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behaviour or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.

 The CORE team has also won the Vannevar Bush Best Paper Award at JCDL 2019, one of the most highly recognised digital libraries conference in the world, for our work on analysing how soon authors deposit into repositories, which was driven by CORE data. A
The CORE team has also won the Vannevar Bush Best Paper Award at JCDL 2019, one of the most highly recognised digital libraries conference in the world, for our work on analysing how soon authors deposit into repositories, which was driven by CORE data. A